import requests
from huggingface_hub import hf_api
import pandas as pd
import matplotlib.pyplot as plt
import richA (very brief) intro to exploring metadata on the Hugging Face Hub
How we can use the
huggingface_hub library to explore metadata on the Hugging Face Hub.
The Hugging Face Hub has become the de facto place to share machine learning models and datasets. As the number of models and datasets grow the challenge of finding the right model or dataset for your needs may become more challenging. There are various ways in which we can try and make it easier for people to find relevant models and datasets. One of these is by associating metadata with datasets and models. This blog post will (very briefly) begin to explore metadata on the Hugging Face Hub. Often you’ll want to explore models and datasets via the Hub website but this isn’t the only way to explore the Hub. As part of the process of exploring metadata on the Hugging Face Hub we’ll briefly look at how we can use the huggingface_hub library to programmatically interact with the Hub.
Library imports
For this post we’ll need a few libraries, pandas, requests and matplotlib are likely old friends (or foes…). The huggingface_hub library might be new to you but will soon become a good friend too! The rich library is fantastically useful for quickly getting familiar with a library (i.e. avoiding reading all the docs!) so we’ll import that too.
%matplotlib inline
plt.style.use("ggplot")We’ll instantiate an instance of the HfApi class.
api = hf_api.HfApi()We can use rich inspect to get a better sense of what a function or class instance is all about. Let’s see what methods the api has.
rich.inspect(api, methods=True)╭──────────────────────────────────── <class 'huggingface_hub.hf_api.HfApi'> ─────────────────────────────────────╮ │ ╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ │ │ │ <huggingface_hub.hf_api.HfApi object at 0x136a2ce80> │ │ │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ │ │ │ │ endpoint = 'https://huggingface.co' │ │ token = None │ │ change_discussion_status = def change_discussion_status(repo_id: str, discussion_num: int, new_status: │ │ Literal['open', 'closed'], *, token: Optional[str] = None, comment: Optional[str] = │ │ None, repo_type: Optional[str] = None) -> │ │ huggingface_hub.community.DiscussionStatusChange: Closes or re-opens a Discussion or │ │ Pull Request. │ │ comment_discussion = def comment_discussion(repo_id: str, discussion_num: int, comment: str, *, token: │ │ Optional[str] = None, repo_type: Optional[str] = None) -> │ │ huggingface_hub.community.DiscussionComment: Creates a new comment on the given │ │ Discussion. │ │ create_branch = def create_branch(repo_id: str, *, branch: str, token: Optional[str] = None, │ │ repo_type: Optional[str] = None) -> None: Create a new branch from `main` on a repo │ │ on the Hub. │ │ create_commit = def create_commit(repo_id: str, operations: │ │ Iterable[Union[huggingface_hub._commit_api.CommitOperationAdd, │ │ huggingface_hub._commit_api.CommitOperationDelete]], *, commit_message: str, │ │ commit_description: Optional[str] = None, token: Optional[str] = None, repo_type: │ │ Optional[str] = None, revision: Optional[str] = None, create_pr: Optional[bool] = │ │ None, num_threads: int = 5, parent_commit: Optional[str] = None) -> │ │ huggingface_hub.hf_api.CommitInfo: Creates a commit in the given repo, deleting & │ │ uploading files as needed. │ │ create_discussion = def create_discussion(repo_id: str, title: str, *, token: Optional[str] = None, │ │ description: Optional[str] = None, repo_type: Optional[str] = None, pull_request: │ │ bool = False) -> huggingface_hub.community.DiscussionWithDetails: Creates a │ │ Discussion or Pull Request. │ │ create_pull_request = def create_pull_request(repo_id: str, title: str, *, token: Optional[str] = None, │ │ description: Optional[str] = None, repo_type: Optional[str] = None) -> │ │ huggingface_hub.community.DiscussionWithDetails: Creates a Pull Request . Pull │ │ Requests created programmatically will be in `"draft"` status. │ │ create_repo = def create_repo(repo_id: str, *, token: Optional[str] = None, private: bool = False, │ │ repo_type: Optional[str] = None, exist_ok: bool = False, space_sdk: Optional[str] = │ │ None) -> str: Create an empty repo on the HuggingFace Hub. │ │ create_tag = def create_tag(repo_id: str, *, tag: str, tag_message: Optional[str] = None, │ │ revision: Optional[str] = None, token: Optional[str] = None, repo_type: │ │ Optional[str] = None) -> None: Tag a given commit of a repo on the Hub. │ │ dataset_info = def dataset_info(repo_id: str, *, revision: Optional[str] = None, timeout: │ │ Optional[float] = None, files_metadata: bool = False, token: Union[bool, str, │ │ NoneType] = None) -> huggingface_hub.hf_api.DatasetInfo: Get info on one specific │ │ dataset on huggingface.co. │ │ delete_branch = def delete_branch(repo_id: str, *, branch: str, token: Optional[str] = None, │ │ repo_type: Optional[str] = None) -> None: Delete a branch from a repo on the Hub. │ │ delete_file = def delete_file(path_in_repo: str, repo_id: str, *, token: Optional[str] = None, │ │ repo_type: Optional[str] = None, revision: Optional[str] = None, commit_message: │ │ Optional[str] = None, commit_description: Optional[str] = None, create_pr: │ │ Optional[bool] = None, parent_commit: Optional[str] = None) -> │ │ huggingface_hub.hf_api.CommitInfo: Deletes a file in the given repo. │ │ delete_folder = def delete_folder(path_in_repo: str, repo_id: str, *, token: Optional[str] = None, │ │ repo_type: Optional[str] = None, revision: Optional[str] = None, commit_message: │ │ Optional[str] = None, commit_description: Optional[str] = None, create_pr: │ │ Optional[bool] = None, parent_commit: Optional[str] = None) -> │ │ huggingface_hub.hf_api.CommitInfo: Deletes a folder in the given repo. │ │ delete_repo = def delete_repo(repo_id: str, *, token: Optional[str] = None, repo_type: │ │ Optional[str] = None): Delete a repo from the HuggingFace Hub. CAUTION: this is │ │ irreversible. │ │ delete_tag = def delete_tag(repo_id: str, *, tag: str, token: Optional[str] = None, repo_type: │ │ Optional[str] = None) -> None: Delete a tag from a repo on the Hub. │ │ edit_discussion_comment = def edit_discussion_comment(repo_id: str, discussion_num: int, comment_id: str, │ │ new_content: str, *, token: Optional[str] = None, repo_type: Optional[str] = None) │ │ -> huggingface_hub.community.DiscussionComment: Edits a comment on a Discussion / │ │ Pull Request. │ │ get_dataset_tags = def get_dataset_tags() -> huggingface_hub.utils.endpoint_helpers.DatasetTags: Gets │ │ all valid dataset tags as a nested namespace object. │ │ get_discussion_details = def get_discussion_details(repo_id: str, discussion_num: int, *, repo_type: │ │ Optional[str] = None, token: Optional[str] = None) -> │ │ huggingface_hub.community.DiscussionWithDetails: Fetches a Discussion's / Pull │ │ Request 's details from the Hub. │ │ get_full_repo_name = def get_full_repo_name(model_id: str, *, organization: Optional[str] = None, token: │ │ Union[bool, str, NoneType] = None): │ │ Returns the repository name for a given model ID and optional │ │ organization. │ │ get_model_tags = def get_model_tags() -> huggingface_hub.utils.endpoint_helpers.ModelTags: Gets all │ │ valid model tags as a nested namespace object │ │ get_repo_discussions = def get_repo_discussions(repo_id: str, *, repo_type: Optional[str] = None, token: │ │ Optional[str] = None) -> Iterator[huggingface_hub.community.Discussion]: Fetches │ │ Discussions and Pull Requests for the given repo. │ │ hide_discussion_comment = def hide_discussion_comment(repo_id: str, discussion_num: int, comment_id: str, *, │ │ token: Optional[str] = None, repo_type: Optional[str] = None) -> │ │ huggingface_hub.community.DiscussionComment: Hides a comment on a Discussion / Pull │ │ Request. │ │ list_datasets = def list_datasets(*, filter: │ │ Union[huggingface_hub.utils.endpoint_helpers.DatasetFilter, str, Iterable[str], │ │ NoneType] = None, author: Optional[str] = None, search: Optional[str] = None, sort: │ │ Union[Literal['lastModified'], str, NoneType] = None, direction: │ │ Optional[Literal[-1]] = None, limit: Optional[int] = None, cardData: Optional[bool] │ │ = None, full: Optional[bool] = None, token: Optional[str] = None) -> │ │ List[huggingface_hub.hf_api.DatasetInfo]: Get the list of all the datasets on │ │ huggingface.co │ │ list_metrics = def list_metrics() -> List[huggingface_hub.hf_api.MetricInfo]: Get the public list │ │ of all the metrics on huggingface.co │ │ list_models = def list_models(*, filter: Union[huggingface_hub.utils.endpoint_helpers.ModelFilter, │ │ str, Iterable[str], NoneType] = None, author: Optional[str] = None, search: │ │ Optional[str] = None, emissions_thresholds: Optional[Tuple[float, float]] = None, │ │ sort: Union[Literal['lastModified'], str, NoneType] = None, direction: │ │ Optional[Literal[-1]] = None, limit: Optional[int] = None, full: Optional[bool] = │ │ None, cardData: bool = False, fetch_config: bool = False, token: Union[bool, str, │ │ NoneType] = None) -> List[huggingface_hub.hf_api.ModelInfo]: Get the list of all the │ │ models on huggingface.co │ │ list_repo_files = def list_repo_files(repo_id: str, *, revision: Optional[str] = None, repo_type: │ │ Optional[str] = None, timeout: Optional[float] = None, token: Union[bool, str, │ │ NoneType] = None) -> List[str]: Get the list of files in a given repo. │ │ list_spaces = def list_spaces(*, filter: Union[str, Iterable[str], NoneType] = None, author: │ │ Optional[str] = None, search: Optional[str] = None, sort: │ │ Union[Literal['lastModified'], str, NoneType] = None, direction: │ │ Optional[Literal[-1]] = None, limit: Optional[int] = None, datasets: Union[str, │ │ Iterable[str], NoneType] = None, models: Union[str, Iterable[str], NoneType] = None, │ │ linked: bool = False, full: Optional[bool] = None, token: Optional[str] = None) -> │ │ List[huggingface_hub.hf_api.SpaceInfo]: Get the public list of all Spaces on │ │ huggingface.co │ │ merge_pull_request = def merge_pull_request(repo_id: str, discussion_num: int, *, token: Optional[str] = │ │ None, comment: Optional[str] = None, repo_type: Optional[str] = None): Merges a Pull │ │ Request. │ │ model_info = def model_info(repo_id: str, *, revision: Optional[str] = None, timeout: │ │ Optional[float] = None, securityStatus: Optional[bool] = None, files_metadata: bool │ │ = False, token: Union[bool, str, NoneType] = None) -> │ │ huggingface_hub.hf_api.ModelInfo: Get info on one specific model on huggingface.co │ │ move_repo = def move_repo(from_id: str, to_id: str, *, repo_type: Optional[str] = None, token: │ │ Optional[str] = None): Moving a repository from namespace1/repo_name1 to │ │ namespace2/repo_name2 │ │ rename_discussion = def rename_discussion(repo_id: str, discussion_num: int, new_title: str, *, token: │ │ Optional[str] = None, repo_type: Optional[str] = None) -> │ │ huggingface_hub.community.DiscussionTitleChange: Renames a Discussion. │ │ repo_info = def repo_info(repo_id: str, *, revision: Optional[str] = None, repo_type: │ │ Optional[str] = None, timeout: Optional[float] = None, files_metadata: bool = False, │ │ token: Union[bool, str, NoneType] = None) -> Union[huggingface_hub.hf_api.ModelInfo, │ │ huggingface_hub.hf_api.DatasetInfo, huggingface_hub.hf_api.SpaceInfo]: Get the info │ │ object for a given repo of a given type. │ │ set_access_token = def set_access_token(access_token: str): │ │ Saves the passed access token so git can correctly authenticate the │ │ user. │ │ space_info = def space_info(repo_id: str, *, revision: Optional[str] = None, timeout: │ │ Optional[float] = None, files_metadata: bool = False, token: Union[bool, str, │ │ NoneType] = None) -> huggingface_hub.hf_api.SpaceInfo: Get info on one specific │ │ Space on huggingface.co. │ │ unset_access_token = def unset_access_token(): Resets the user's access token. │ │ update_repo_visibility = def update_repo_visibility(repo_id: str, private: bool = False, *, token: │ │ Optional[str] = None, organization: Optional[str] = None, repo_type: Optional[str] = │ │ None, name: Optional[str] = None) -> Dict[str, bool]: Update the visibility setting │ │ of a repository. │ │ upload_file = def upload_file(*, path_or_fileobj: Union[str, bytes, BinaryIO], path_in_repo: str, │ │ repo_id: str, token: Optional[str] = None, repo_type: Optional[str] = None, │ │ revision: Optional[str] = None, commit_message: Optional[str] = None, │ │ commit_description: Optional[str] = None, create_pr: Optional[bool] = None, │ │ parent_commit: Optional[str] = None) -> str: │ │ Upload a local file (up to 50 GB) to the given repo. The upload is done │ │ through a HTTP post request, and doesn't require git or git-lfs to be │ │ installed. │ │ upload_folder = def upload_folder(*, repo_id: str, folder_path: Union[str, pathlib.Path], │ │ path_in_repo: Optional[str] = None, commit_message: Optional[str] = None, │ │ commit_description: Optional[str] = None, token: Optional[str] = None, repo_type: │ │ Optional[str] = None, revision: Optional[str] = None, create_pr: Optional[bool] = │ │ None, parent_commit: Optional[str] = None, allow_patterns: Union[List[str], str, │ │ NoneType] = None, ignore_patterns: Union[List[str], str, NoneType] = None): │ │ Upload a local folder to the given repo. The upload is done │ │ through a HTTP requests, and doesn't require git or git-lfs to be │ │ installed. │ │ whoami = def whoami(token: Optional[str] = None) -> Dict: Call HF API to know "whoami". │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
You’ll see from looking through this there is a bunch of different things we can now do programmatically via the hub. For this post we’re interested in the list_datasets and list_models methods. If we look at one of these we can see it has a bunch of different options we can use when listing datasets or models.
rich.inspect(api.list_models)╭─────────── <bound method HfApi.list_models of <huggingface_hub.hf_api.HfApi object at 0x136a2ce80>> ────────────╮ │ def HfApi.list_models(*, filter: Union[huggingface_hub.utils.endpoint_helpers.ModelFilter, str, Iterable[str], │ │ NoneType] = None, author: Optional[str] = None, search: Optional[str] = None, emissions_thresholds: │ │ Optional[Tuple[float, float]] = None, sort: Union[Literal['lastModified'], str, NoneType] = None, direction: │ │ Optional[Literal[-1]] = None, limit: Optional[int] = None, full: Optional[bool] = None, cardData: bool = False, │ │ fetch_config: bool = False, token: Union[bool, str, NoneType] = None) -> │ │ List[huggingface_hub.hf_api.ModelInfo]: │ │ │ │ Get the list of all the models on huggingface.co │ │ │ │ 28 attribute(s) not shown. Run inspect(inspect) for options. │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
For our use case we want everything, so we set limit=None, we don’t want any filters so we set this to None (this is the default behaviour, but we set them explicitly here to make it clearer for our future selves). We also set full=True so we get back more verbose information about our dataset and models. We also wrap the result in iter and list since the behaviour of these methods will change in future versions to support paging.
hub_datasets = list(iter(api.list_datasets(limit=None, filter=None, full=True)))hub_models = list(iter(api.list_models(limit=None, filter=None, full=True)))Let’s peek at an example of what we get back
hub_models[0]ModelInfo: {
modelId: albert-base-v1
sha: aeffd769076a5c4f83b2546aea99ca45a15a5da4
lastModified: 2021-01-13T15:08:24.000Z
tags: ['pytorch', 'tf', 'albert', 'fill-mask', 'en', 'dataset:bookcorpus', 'dataset:wikipedia', 'arxiv:1909.11942', 'transformers', 'exbert', 'license:apache-2.0', 'autotrain_compatible', 'has_space']
pipeline_tag: fill-mask
siblings: [RepoFile(rfilename='.gitattributes', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='README.md', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='config.json', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='pytorch_model.bin', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='spiece.model', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='tf_model.h5', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='tokenizer.json', size='None', blob_id='None', lfs='None'), RepoFile(rfilename='with-prefix-tf_model.h5', size='None', blob_id='None', lfs='None')]
private: False
author: None
config: None
securityStatus: None
_id: 621ffdc036468d709f174328
id: albert-base-v1
gitalyUid: 4f35551ea371da7a8762caab54319a54ade836044f0ca7690d21e86b159867eb
likes: 1
downloads: 75182
library_name: transformers
}hub_datasets[0]DatasetInfo: {
id: acronym_identification
sha: 173af1516c409eb4596bc63a69626bdb5584c40c
lastModified: 2022-11-18T17:25:49.000Z
tags: ['task_categories:token-classification', 'annotations_creators:expert-generated', 'language_creators:found', 'multilinguality:monolingual', 'size_categories:10K<n<100K', 'source_datasets:original', 'language:en', 'license:mit', 'acronym-identification', 'arxiv:2010.14678']
private: False
author: None
description: Acronym identification training and development sets for the acronym identification task at SDU@AAAI-21.
citation: @inproceedings{veyseh-et-al-2020-what,
title={{What Does This Acronym Mean? Introducing a New Dataset for Acronym Identification and Disambiguation}},
author={Amir Pouran Ben Veyseh and Franck Dernoncourt and Quan Hung Tran and Thien Huu Nguyen},
year={2020},
booktitle={Proceedings of COLING},
link={https://arxiv.org/pdf/2010.14678v1.pdf}
}
cardData: {'annotations_creators': ['expert-generated'], 'language_creators': ['found'], 'language': ['en'], 'license': ['mit'], 'multilinguality': ['monolingual'], 'size_categories': ['10K<n<100K'], 'source_datasets': ['original'], 'task_categories': ['token-classification'], 'task_ids': [], 'paperswithcode_id': 'acronym-identification', 'pretty_name': 'Acronym Identification Dataset', 'train-eval-index': [{'config': 'default', 'task': 'token-classification', 'task_id': 'entity_extraction', 'splits': {'eval_split': 'test'}, 'col_mapping': {'tokens': 'tokens', 'labels': 'tags'}}], 'tags': ['acronym-identification'], 'dataset_info': {'features': [{'name': 'id', 'dtype': 'string'}, {'name': 'tokens', 'sequence': 'string'}, {'name': 'labels', 'sequence': {'class_label': {'names': {'0': 'B-long', '1': 'B-short', '2': 'I-long', '3': 'I-short', '4': 'O'}}}}], 'splits': [{'name': 'train', 'num_bytes': 7792803, 'num_examples': 14006}, {'name': 'validation', 'num_bytes': 952705, 'num_examples': 1717}, {'name': 'test', 'num_bytes': 987728, 'num_examples': 1750}], 'download_size': 8556464, 'dataset_size': 9733236}}
siblings: []
_id: 621ffdd236468d709f181d58
disabled: False
gated: False
gitalyUid: 6570517623fa521aa189178e7c7e73d9d88c01b295204edef97f389a15eae144
likes: 9
downloads: 6074
paperswithcode_id: acronym-identification
}Since we want both models and datasets we create a dictionary which stores the types of item i.e. is it a dataset or a model.
hub_data = {"model": hub_models, "dataset": hub_datasets}We’ll be putting our data inside a pandas DataFrame, so we’ll grab the .__dict__ attribute for each hub item, so it’s more pandas friendly.
hub_item_dict = []
for hub_type, hub_item in hub_data.items():
for item in hub_item:
data = item.__dict__
data["type"] = hub_type
hub_item_dict.append(data)df = pd.DataFrame.from_dict(hub_item_dict)How many hub items do we have?
len(df)151343What info do we have?
df.columnsIndex(['modelId', 'sha', 'lastModified', 'tags', 'pipeline_tag', 'siblings',
'private', 'author', 'config', 'securityStatus', '_id', 'id',
'gitalyUid', 'likes', 'downloads', 'library_name', 'type',
'description', 'citation', 'cardData', 'disabled', 'gated',
'paperswithcode_id'],
dtype='object')Tags
Models and datasets have a bunch of metadata i.e. last modified and number of downloads. We’ll focus on tags here. Let’s start by looking at a single example.
df.loc[30, "tags"]['pytorch',
'tf',
'rust',
'safetensors',
'distilbert',
'text-classification',
'en',
'dataset:sst2',
'dataset:glue',
'doi:10.57967/hf/0181',
'transformers',
'license:apache-2.0',
'model-index',
'has_space']We can see that tags capture can relate to tasks i.e. text-classification, libraries supported i.e. tf, or the licence associated with a model or dataset. As a starting point for exploring tags we can take a look at how many tags models and datasets have. We’ll add a new column to capture this number.
def calculate_number_of_tags(tags: [str]) -> int:
return len(tags)df["number_of_tags"] = df["tags"].apply(lambda x: calculate_number_of_tags(x))We can now use describe to see the breakdown of this number.
df.number_of_tags.describe()count 151343.000000
mean 3.855566
std 6.878613
min 0.000000
25% 0.000000
50% 4.000000
75% 6.000000
max 650.000000
Name: number_of_tags, dtype: float64We can see that we have quite a range of tag numbers ranging from 0 to 650! If your brain works anything like mine you probably want to know what this high value is about!
df[df.number_of_tags > 640][["id", "tags"]]| id | tags | |
|---|---|---|
| 136372 | bible-nlp/biblenlp-corpus | [task_categories:translation, annotations_crea... |
df[df.number_of_tags > 640]["tags"].tolist()[['task_categories:translation',
'annotations_creators:no-annotation',
'language_creators:expert-generated',
'multilinguality:translation',
'multilinguality:multilingual',
'size_categories:1M<n<10M',
'source_datasets:original',
'language:aau',
'language:aaz',
'language:abx',
'language:aby',
'language:acf',
'language:acu',
'language:adz',
'language:aey',
'language:agd',
'language:agg',
'language:agm',
'language:agn',
'language:agr',
'language:agu',
'language:aia',
'language:ake',
'language:alp',
'language:alq',
'language:als',
'language:aly',
'language:ame',
'language:amk',
'language:amp',
'language:amr',
'language:amu',
'language:anh',
'language:anv',
'language:aoi',
'language:aoj',
'language:apb',
'language:apn',
'language:apu',
'language:apy',
'language:arb',
'language:arl',
'language:arn',
'language:arp',
'language:aso',
'language:ata',
'language:atb',
'language:atd',
'language:atg',
'language:auc',
'language:aui',
'language:auy',
'language:avt',
'language:awb',
'language:awk',
'language:awx',
'language:azg',
'language:azz',
'language:bao',
'language:bbb',
'language:bbr',
'language:bch',
'language:bco',
'language:bdd',
'language:bea',
'language:bel',
'language:bgs',
'language:bgt',
'language:bhg',
'language:bhl',
'language:big',
'language:bjr',
'language:bjv',
'language:bkd',
'language:bki',
'language:bkq',
'language:bkx',
'language:bla',
'language:blw',
'language:blz',
'language:bmh',
'language:bmk',
'language:bmr',
'language:bnp',
'language:boa',
'language:boj',
'language:bon',
'language:box',
'language:bqc',
'language:bre',
'language:bsn',
'language:bsp',
'language:bss',
'language:buk',
'language:bus',
'language:bvr',
'language:bxh',
'language:byx',
'language:bzd',
'language:bzj',
'language:cab',
'language:caf',
'language:cao',
'language:cap',
'language:car',
'language:cav',
'language:cax',
'language:cbc',
'language:cbi',
'language:cbk',
'language:cbr',
'language:cbs',
'language:cbt',
'language:cbu',
'language:cbv',
'language:cco',
'language:ces',
'language:cgc',
'language:cha',
'language:chd',
'language:chf',
'language:chk',
'language:chq',
'language:chz',
'language:cjo',
'language:cjv',
'language:cle',
'language:clu',
'language:cme',
'language:cmn',
'language:cni',
'language:cnl',
'language:cnt',
'language:cof',
'language:con',
'language:cop',
'language:cot',
'language:cpa',
'language:cpb',
'language:cpc',
'language:cpu',
'language:crn',
'language:crx',
'language:cso',
'language:cta',
'language:ctp',
'language:ctu',
'language:cub',
'language:cuc',
'language:cui',
'language:cut',
'language:cux',
'language:cwe',
'language:daa',
'language:dad',
'language:dah',
'language:ded',
'language:deu',
'language:dgr',
'language:dgz',
'language:dif',
'language:dik',
'language:dji',
'language:djk',
'language:dob',
'language:dwr',
'language:dww',
'language:dwy',
'language:eko',
'language:emi',
'language:emp',
'language:eng',
'language:epo',
'language:eri',
'language:ese',
'language:etr',
'language:faa',
'language:fai',
'language:far',
'language:for',
'language:fra',
'language:fuf',
'language:gai',
'language:gam',
'language:gaw',
'language:gdn',
'language:gdr',
'language:geb',
'language:gfk',
'language:ghs',
'language:gia',
'language:glk',
'language:gmv',
'language:gng',
'language:gnn',
'language:gnw',
'language:gof',
'language:grc',
'language:gub',
'language:guh',
'language:gui',
'language:gul',
'language:gum',
'language:guo',
'language:gvc',
'language:gvf',
'language:gwi',
'language:gym',
'language:gyr',
'language:hat',
'language:haw',
'language:hbo',
'language:hch',
'language:heb',
'language:heg',
'language:hix',
'language:hla',
'language:hlt',
'language:hns',
'language:hop',
'language:hrv',
'language:hub',
'language:hui',
'language:hus',
'language:huu',
'language:huv',
'language:hvn',
'language:ign',
'language:ikk',
'language:ikw',
'language:imo',
'language:inb',
'language:ind',
'language:ino',
'language:iou',
'language:ipi',
'language:ita',
'language:jac',
'language:jao',
'language:jic',
'language:jiv',
'language:jpn',
'language:jvn',
'language:kaq',
'language:kbc',
'language:kbh',
'language:kbm',
'language:kdc',
'language:kde',
'language:kdl',
'language:kek',
'language:ken',
'language:kew',
'language:kgk',
'language:kgp',
'language:khs',
'language:kje',
'language:kjs',
'language:kkc',
'language:kky',
'language:klt',
'language:klv',
'language:kms',
'language:kmu',
'language:kne',
'language:knf',
'language:knj',
'language:kos',
'language:kpf',
'language:kpg',
'language:kpj',
'language:kpw',
'language:kqa',
'language:kqc',
'language:kqf',
'language:kql',
'language:kqw',
'language:ksj',
'language:ksr',
'language:ktm',
'language:kto',
'language:kud',
'language:kue',
'language:kup',
'language:kvn',
'language:kwd',
'language:kwf',
'language:kwi',
'language:kwj',
'language:kyf',
'language:kyg',
'language:kyq',
'language:kyz',
'language:kze',
'language:lac',
'language:lat',
'language:lbb',
'language:leu',
'language:lex',
'language:lgl',
'language:lid',
'language:lif',
'language:lww',
'language:maa',
'language:maj',
'language:maq',
'language:mau',
'language:mav',
'language:maz',
'language:mbb',
'language:mbc',
'language:mbh',
'language:mbl',
'language:mbt',
'language:mca',
'language:mcb',
'language:mcd',
'language:mcf',
'language:mcp',
'language:mdy',
'language:med',
'language:mee',
'language:mek',
'language:meq',
'language:met',
'language:meu',
'language:mgh',
'language:mgw',
'language:mhl',
'language:mib',
'language:mic',
'language:mie',
'language:mig',
'language:mih',
'language:mil',
'language:mio',
'language:mir',
'language:mit',
'language:miz',
'language:mjc',
'language:mkn',
'language:mks',
'language:mlh',
'language:mlp',
'language:mmx',
'language:mna',
'language:mop',
'language:mox',
'language:mph',
'language:mpj',
'language:mpm',
'language:mpp',
'language:mps',
'language:mpx',
'language:mqb',
'language:mqj',
'language:msb',
'language:msc',
'language:msk',
'language:msm',
'language:msy',
'language:mti',
'language:muy',
'language:mva',
'language:mvn',
'language:mwc',
'language:mxb',
'language:mxp',
'language:mxq',
'language:mxt',
'language:myu',
'language:myw',
'language:myy',
'language:mzz',
'language:nab',
'language:naf',
'language:nak',
'language:nay',
'language:nbq',
'language:nca',
'language:nch',
'language:ncj',
'language:ncl',
'language:ncu',
'language:ndj',
'language:nfa',
'language:ngp',
'language:ngu',
'language:nhg',
'language:nhi',
'language:nho',
'language:nhr',
'language:nhu',
'language:nhw',
'language:nhy',
'language:nif',
'language:nin',
'language:nko',
'language:nld',
'language:nlg',
'language:nna',
'language:nnq',
'language:not',
'language:nou',
'language:npl',
'language:nsn',
'language:nss',
'language:ntj',
'language:ntp',
'language:nwi',
'language:nyu',
'language:obo',
'language:ong',
'language:ons',
'language:ood',
'language:opm',
'language:ote',
'language:otm',
'language:otn',
'language:otq',
'language:ots',
'language:pab',
'language:pad',
'language:pah',
'language:pao',
'language:pes',
'language:pib',
'language:pio',
'language:pir',
'language:pjt',
'language:plu',
'language:pma',
'language:poe',
'language:poi',
'language:pon',
'language:poy',
'language:ppo',
'language:prf',
'language:pri',
'language:ptp',
'language:ptu',
'language:pwg',
'language:quc',
'language:quf',
'language:quh',
'language:qul',
'language:qup',
'language:qvc',
'language:qve',
'language:qvh',
'language:qvm',
'language:qvn',
'language:qvs',
'language:qvw',
'language:qvz',
'language:qwh',
'language:qxh',
'language:qxn',
'language:qxo',
'language:rai',
'language:rkb',
'language:rmc',
'language:roo',
'language:rop',
'language:rro',
'language:ruf',
'language:rug',
'language:rus',
'language:sab',
'language:san',
'language:sbe',
'language:seh',
'language:sey',
'language:sgz',
'language:shj',
'language:shp',
'language:sim',
'language:sja',
'language:sll',
'language:smk',
'language:snc',
'language:snn',
'language:sny',
'language:som',
'language:soq',
'language:spa',
'language:spl',
'language:spm',
'language:sps',
'language:spy',
'language:sri',
'language:srm',
'language:srn',
'language:srp',
'language:srq',
'language:ssd',
'language:ssg',
'language:ssx',
'language:stp',
'language:sua',
'language:sue',
'language:sus',
'language:suz',
'language:swe',
'language:swh',
'language:swp',
'language:sxb',
'language:tac',
'language:tav',
'language:tbc',
'language:tbl',
'language:tbo',
'language:tbz',
'language:tca',
'language:tee',
'language:ter',
'language:tew',
'language:tfr',
'language:tgp',
'language:tif',
'language:tim',
'language:tiy',
'language:tke',
'language:tku',
'language:tna',
'language:tnc',
'language:tnn',
'language:tnp',
'language:toc',
'language:tod',
'language:toj',
'language:ton',
'language:too',
'language:top',
'language:tos',
'language:tpt',
'language:trc',
'language:tsw',
'language:ttc',
'language:tue',
'language:tuo',
'language:txu',
'language:ubr',
'language:udu',
'language:ukr',
'language:uli',
'language:ura',
'language:urb',
'language:usa',
'language:usp',
'language:uvl',
'language:vid',
'language:vie',
'language:viv',
'language:vmy',
'language:waj',
'language:wal',
'language:wap',
'language:wat',
'language:wbp',
'language:wed',
'language:wer',
'language:wim',
'language:wmt',
'language:wmw',
'language:wnc',
'language:wnu',
'language:wos',
'language:wrk',
'language:wro',
'language:wsk',
'language:wuv',
'language:xav',
'language:xed',
'language:xla',
'language:xnn',
'language:xon',
'language:xsi',
'language:xtd',
'language:xtm',
'language:yaa',
'language:yad',
'language:yal',
'language:yap',
'language:yaq',
'language:yby',
'language:ycn',
'language:yka',
'language:yml',
'language:yre',
'language:yuj',
'language:yut',
'language:yuw',
'language:yva',
'language:zaa',
'language:zab',
'language:zac',
'language:zad',
'language:zai',
'language:zaj',
'language:zam',
'language:zao',
'language:zar',
'language:zas',
'language:zat',
'language:zav',
'language:zaw',
'language:zca',
'language:zia',
'language:ziw',
'language:zos',
'language:zpc',
'language:zpl',
'language:zpo',
'language:zpq',
'language:zpu',
'language:zpv',
'language:zpz',
'language:zsr',
'language:ztq',
'language:zty',
'language:zyp',
'language:be',
'language:br',
'language:cs',
'language:ch',
'language:zh',
'language:de',
'language:en',
'language:eo',
'language:fr',
'language:ht',
'language:he',
'language:hr',
'language:id',
'language:it',
'language:ja',
'language:la',
'language:nl',
'language:ru',
'language:sa',
'language:so',
'language:es',
'language:sr',
'language:sv',
'language:to',
'language:uk',
'language:vi',
'license:cc-by-4.0',
'license:other']]We can see that in this case many of the tags relate to language. Since the dataset is bible related and the bible has been heavily translated this might not be as surprising.
Although these high-level stats are somewhat interesting we probably want to break these numbers down. At a high level we can groupby datasets vs models.
df.groupby("type")["number_of_tags"].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| type | ||||||||
| dataset | 19576.0 | 2.46935 | 13.137220 | 0.0 | 0.0 | 0.0 | 2.0 | 650.0 |
| model | 131767.0 | 4.06151 | 5.327066 | 0.0 | 0.0 | 4.0 | 6.0 | 413.0 |
We can see that the mean number of tags for models is higher than datasets. We can also see at the 75% percentile models also have more tags compared to datasets. The possible reasons for this (and whether this is a problem or not) is something we may wish to explore further…
Since the hub hosts models from different libraries we may want to also breakdown by library. First let’s grab only the model part of our DataFrame.
models_df = df[df["type"] == "model"]The library_name column contains info about the library. Let’s see how many unique libraries we have.
models_df.library_name.unique().shape(63,)This is quite a few! We can do a groupby on this column
models_df.groupby("library_name")["number_of_tags"].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| library_name | ||||||||
| BERT | 1.0 | 7.0 | NaN | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 |
| Doc-UFCN | 2.0 | 4.0 | 0.000000 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 |
| EveryDream | 2.0 | 7.0 | 0.000000 | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 |
| FastAI | 1.0 | 1.0 | NaN | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| JoeyNMT | 1.0 | 4.0 | NaN | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| ultralytics | 4.0 | 10.0 | 1.414214 | 8.0 | 9.5 | 10.5 | 11.0 | 11.0 |
| ultralyticsplus | 1.0 | 9.0 | NaN | 9.0 | 9.0 | 9.0 | 9.0 | 9.0 |
| yolor | 2.0 | 9.0 | 0.000000 | 9.0 | 9.0 | 9.0 | 9.0 | 9.0 |
| yolov5 | 36.0 | 9.0 | 0.000000 | 9.0 | 9.0 | 9.0 | 9.0 | 9.0 |
| yolov6detect | 1.0 | 10.0 | NaN | 10.0 | 10.0 | 10.0 | 10.0 | 10.0 |
62 rows × 8 columns
We might find this a bit tricky to look at. We may want to only include the top n libraries since some of these libraries may be less well used.
models_df.library_name.value_counts()[:15]transformers 63754
stable-baselines3 3183
diffusers 2802
sentence-transformers 1273
ml-agents 763
keras 470
timm 383
espnet 381
spacy 296
sample-factory 273
adapter-transformers 201
sklearn 113
nemo 103
fastai 99
speechbrain 94
Name: library_name, dtype: int64top_libraries = models_df.library_name.value_counts()[:9].index.to_list()top_libraries_df = models_df[models_df.library_name.isin(top_libraries)]top_libraries_df.groupby("library_name")["number_of_tags"].describe()| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| library_name | ||||||||
| diffusers | 2802.0 | 4.374732 | 2.171226 | 1.0 | 3.0 | 4.0 | 5.0 | 18.0 |
| espnet | 381.0 | 6.965879 | 0.595060 | 3.0 | 7.0 | 7.0 | 7.0 | 9.0 |
| keras | 470.0 | 3.842553 | 14.422674 | 1.0 | 1.0 | 2.0 | 5.0 | 311.0 |
| ml-agents | 763.0 | 6.965924 | 0.273775 | 2.0 | 7.0 | 7.0 | 7.0 | 7.0 |
| sentence-transformers | 1273.0 | 6.984289 | 3.221840 | 2.0 | 6.0 | 6.0 | 7.0 | 36.0 |
| spacy | 296.0 | 4.611486 | 0.985180 | 2.0 | 4.0 | 5.0 | 5.0 | 10.0 |
| stable-baselines3 | 3183.0 | 4.997801 | 0.163426 | 3.0 | 5.0 | 5.0 | 5.0 | 8.0 |
| timm | 383.0 | 3.548303 | 1.315291 | 2.0 | 3.0 | 3.0 | 3.0 | 13.0 |
| transformers | 63754.0 | 6.912037 | 5.262633 | 1.0 | 5.0 | 6.0 | 8.0 | 240.0 |
Let’s take a quick look at some examples from the library with the highest and lowest number or tags.
top_libraries_df[top_libraries_df.library_name == "sentence-transformers"].sample(15)[
"tags"
]6123 [pytorch, gpt_neo, arxiv:2202.08904, sentence-...
2488 [pytorch, distilbert, sentence-transformers, f...
37669 [pytorch, distilbert, sentence-transformers, f...
71483 [pytorch, bert, sentence-transformers, feature...
20710 [pytorch, tf, roberta, ko, sentence-transforme...
27073 [pytorch, tf, jax, roberta, arxiv:1908.10084, ...
92037 [pytorch, mpnet, sentence-transformers, featur...
90320 [pytorch, mpnet, sentence-transformers, featur...
63555 [pytorch, bert, sentence-transformers, feature...
87707 [pytorch, mpnet, sentence-transformers, featur...
80570 [pytorch, bert, sentence-transformers, feature...
111407 [pytorch, bert, sentence-transformers, feature...
82690 [pytorch, mpnet, sentence-transformers, featur...
36217 [pytorch, bert, pl, dataset:Wikipedia, arxiv:1...
100086 [pytorch, roberta, sentence-transformers, feat...
Name: tags, dtype: objecttop_libraries_df[top_libraries_df.library_name == "timm"].sample(15)["tags"]104432 [pytorch, timm, image-classification]
110296 [pytorch, arxiv:2301.00808, timm, image-classi...
24158 [pytorch, timm, image-classification]
26471 [pytorch, timm, image-classification]
104437 [pytorch, timm, image-classification]
61630 [pytorch, dataset:beans, timm, image-classific...
110298 [pytorch, arxiv:2301.00808, timm, image-classi...
104015 [pytorch, timm, image-classification]
101124 [pytorch, timm, image-classification]
57882 [coreml, onnx, en, dataset:imagenet-1k, arxiv:...
83459 [pytorch, timm, image-classification, vision, ...
99461 [pytorch, timm, image-classification]
104029 [pytorch, timm, image-classification]
84402 [pytorch, timm, image-classification, vision, ...
104428 [pytorch, timm, image-classification]
Name: tags, dtype: objectWe can see here that some tags for sentence-transformers are very closely tied to that libraries purpose e.g. the sentence-similarity tag. This tag migth be useful when a user is looking for models to do sentence-similarity but might be less useful if you are trying to choose between models for this task i.e. trying to find the setence-transformer model that will be useful for you. We should be careful, therefore, in treating number of tags as a proxy for quality.
Grouping by pipeline tags
We have a column in our dataframe pipeline tag, which refers to the type of task a model is for. We should be careful relying too much on this but we can have a quick look at how often these are used.
models_df["pipeline_tag"].value_counts()text-classification 14479
text2text-generation 8102
text-generation 7602
reinforcement-learning 6885
token-classification 6386
automatic-speech-recognition 6238
fill-mask 5447
question-answering 3147
feature-extraction 2661
translation 1837
conversational 1770
image-classification 1760
text-to-image 1604
sentence-similarity 1248
summarization 735
unconditional-image-generation 428
text-to-speech 244
audio-classification 234
multiple-choice 169
object-detection 158
image-segmentation 134
audio-to-audio 130
tabular-classification 97
zero-shot-classification 97
image-to-text 76
zero-shot-image-classification 56
video-classification 50
table-question-answering 47
tabular-regression 44
image-to-image 43
depth-estimation 37
document-question-answering 18
visual-question-answering 13
voice-activity-detection 6
other 4
time-series-forecasting 1
Name: pipeline_tag, dtype: int64We may also want to see if there are some type of task that have more tags.
models_df.groupby("pipeline_tag")["number_of_tags"].mean().sort_values().plot.barh()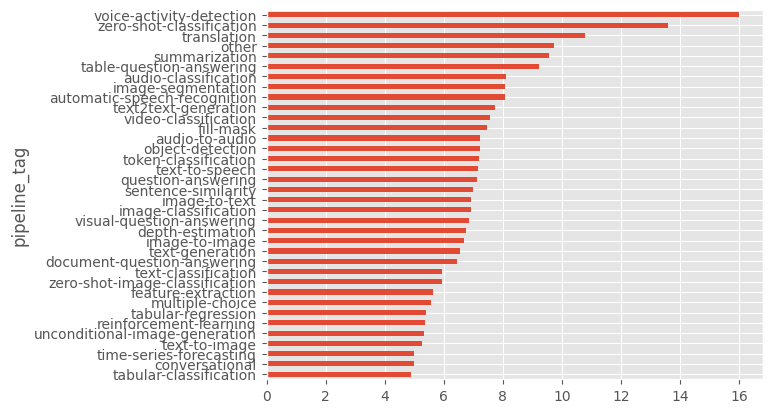
We can also look at the breakdown for a particular task
text_classification_df = models_df[models_df["pipeline_tag"] == "text-classification"]text_classification_df["number_of_tags"].describe()count 14479.000000
mean 5.948822
std 3.718800
min 1.000000
25% 4.000000
50% 5.000000
75% 7.000000
max 240.000000
Name: number_of_tags, dtype: float64Again, we have some extreme outliers
text_classification_df[text_classification_df.number_of_tags > 230][["tags", "modelId"]]| tags | modelId | |
|---|---|---|
| 22457 | [pytorch, tf, roberta, text-classification, mu... | m3hrdadfi/zabanshenas-roberta-base-mix |
| 101628 | [pytorch, canine, text-classification, ace, af... | SebOchs/canine-c-lang-id |
We see that these mostly seem to relate to language. Let’s remove these outliers and look at the distribution in the number of tags without these.
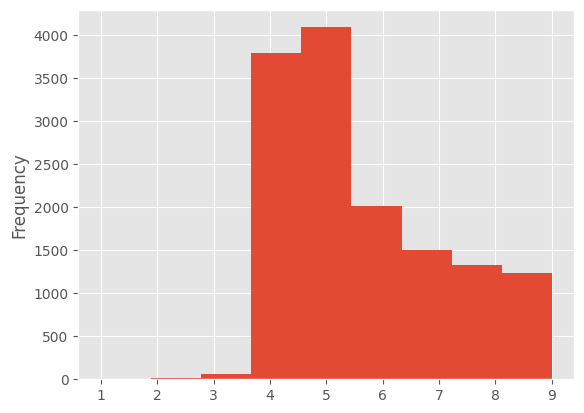
text_classification_df_no_outliers = text_classification_df[
text_classification_df["number_of_tags"]
<= text_classification_df["number_of_tags"].quantile(0.95)
]
text_classification_df_no_outliers["number_of_tags"].plot.hist(bins=9)